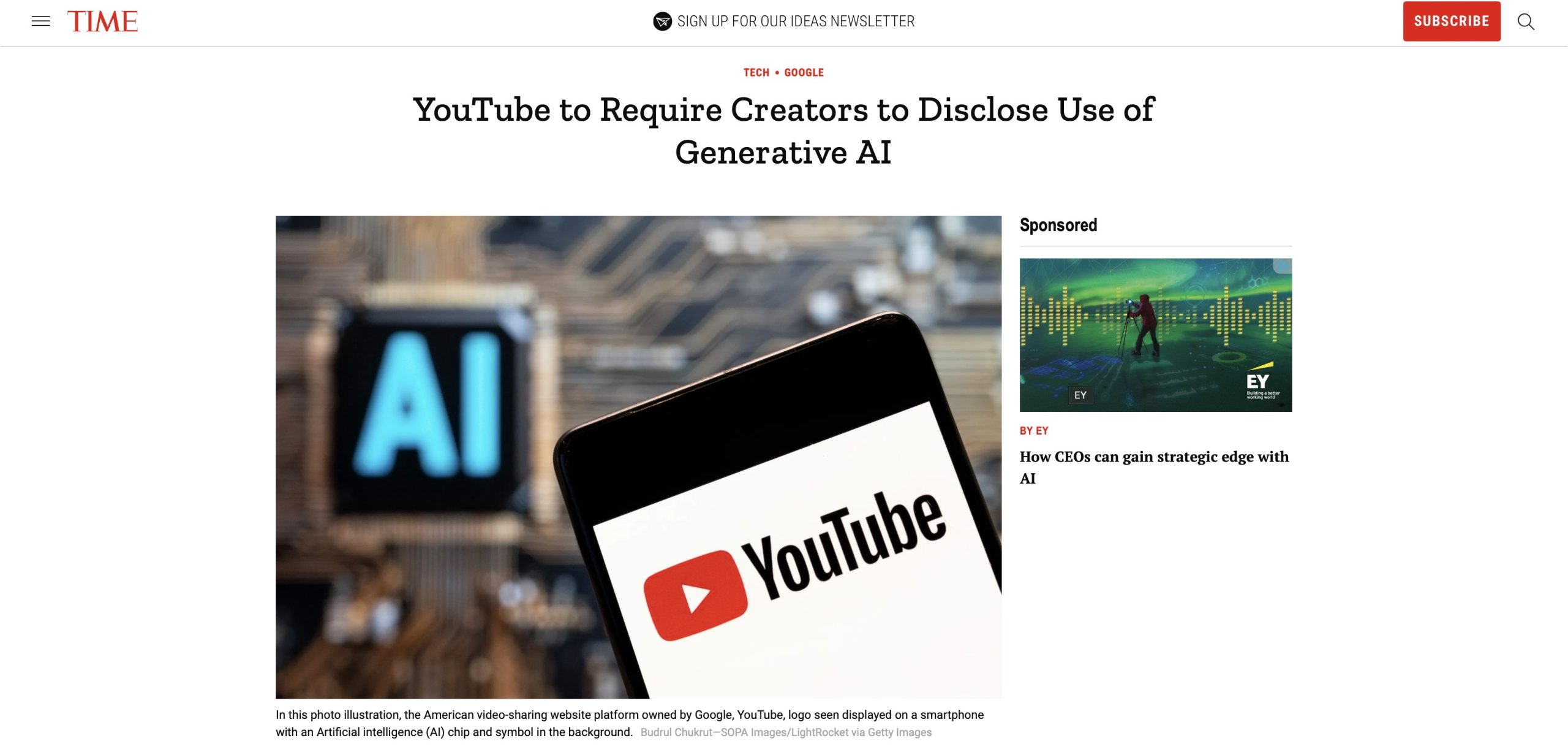
Meet ‘VLOGGER’ by Google, an AI that converts Photo to Talking Video
Get ready to dust off your old photo albums. Google AI has unveiled VLOGGER, a revolutionary system that can transform a single still photo into a lifelike video. This technology, detailed in a research paper titled “VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis,” has the potential to reshape the way we create and consume visual content.
VLOGGER leverages the power of diffusion models, a type of machine learning adept at progressively adding detail to noise. In this case, the “noise” is the photo, and the “detail” is the movement, facial expressions, and body language that bring the person in the picture to life. Users simply provide a picture and an audio clip, and VLOGGER generates a video of the person speaking, complete with natural gestures and lip-syncing.
The implications are vast. Imagine historical figures delivering speeches in living color, or creating explainer videos with an avatar generated from a product image. VLOGGER could revolutionize education, communication, and even entertainment.
Concerns linger. Deepfakes, hyper-realistic AI-generated videos used to spread misinformation, have already become a significant problem. VLOGGER’s ease of use raises the bar for creating convincing forgeries. Google AI acknowledges these concerns, emphasizing the importance of responsible development and transparent usage.
VLOGGER is still under development, and the generated videos, while impressive, aren’t perfect. Some artifacts and glitches may appear. Yet, the technology represents a significant leap forward.
The future of visual content is on the cusp of transformation. VLOGGER offers immense potential, but navigating the ethical considerations will be crucial. As Google refines its AI, the line between captivating storytelling and deceptive manipulation will become increasingly blurry. Only time will tell how this technology shapes our perception of truth and reality on the ever-evolving digital canvas.